ChatGPT与私有数据整合原理
ChatGPT 的出现惊艳了世界,它通过了图灵测试,让人们分不清回答问题的是人还是机器。大家不甘于只在官方的对话页面问答,想利用 GPT 模型的自然语言能力结合私有数据做更多的应用场景,解决模型训练的数据不是实时的问题,同时也解决 OpenAI API tokens 限制的的问题。本文先来分析下这些基本问题如何解决,理解了这个基本原理,就能了解到 ChatGPT 衍生的很多产品,甚至去打造适合自己场景的应用。
Token 限制
OpenAI 提供了 OpenAPI 供第三方调用,但是无论你调用什么接口,每个模型都有对应的 token 数量限制,这意味着你不可能传输大量的数据。比如最新的 gpt-4 模型限制了 8,192 tokens,如果你想要提供大量的上下文信息后,这在单次的接口处理上是不可能的事情。
这里可以通过 Tokenizer 来计算你的文本对应的 token 数量,一般少量的 context 还是可以接受的,但是大量的 context 我们就得考虑接下来介绍的方法。
Embeddings 模型
OpenAI 提供的不仅仅是用于文本填充或问答的功能的 GPT 模型,还有其他许多模型。比如 DALL·E 模型可以根据文字生成图片,Whisper 模型可以通过声音转换文本,Moderation 可以通过文本内容识别是否涉及暴力等有害内容,还有一个 Embeddings 模型可以用于计算文本的关联性。
那 Embeddings 模型计算文本的关联性可以用于什么场景呢?官方文档举了几个场景:
- 搜索(结果按查询字符串相关性排序)
- 聚类(按相似性分组文本字符串)
- 推荐(推荐具有相关文本字符串的项目)
- 异常检测(识别相关性较小的离群值)
- 多样性测量(分析相似性分布)
- 分类(按最相似的标签对文本字符串进行分类)
接下来我们通过接口请求来看看这个模型是怎么使用的,首先我们把文本数据放到 input 字段里,这个字段也有 token 限制,如果是大文本还需要做些预处理切割。
1 | curl https://api.openai.com/v1/embeddings \ |
传入的文本后调用接口的响应内容里 data.embedding 就是我们要的数据,可以看出来这是一个浮点型数组,目前这个数组有 1536 个元素,这其实就是原始文本内容对应的向量。
1 | { |
向量相似性与数据库
原始文本被拆分成多个片段后,通过 Embeddings 模型生成对应的数字向量,我们需要提问的问题也可以生成向量,这样就可以找到问题与多个原始文本片段的相似性,再做个 rank,可以获得与这个问题相关度最高的文本片段。
通过向量如何计算相似度呢?这里可以利用数学里的 余弦相似性 来计算,想象一下在二维空间里,两个向量的夹角越小,这两个向量的方向就越一致,也即相关度会越高。可以利用以下公式计算。
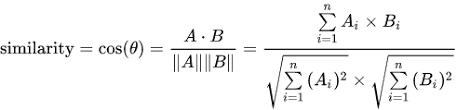
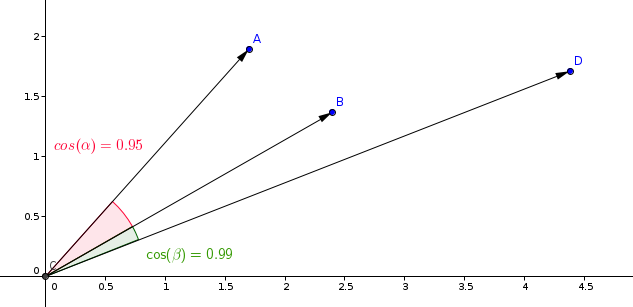
但是在上面获取的向量并不是一个二维的向量,而是拥有 1536 个数据的向量,这个时候计算会复杂一点,当然我们可以不用自己计算,直接利用向量数据库即可。所以通过 Embedings 模型获取到的结果用常规的关系数据库如 MySQL 存储在计算时并不方便,需要专门的向量数据库。
目前比较知名 vector database 的有:
其余的不太熟悉不一一列举,大家可以自行搜索 vector database 找到合适的向量数据库。利用好向量数据库存好 vector 和 payload,再利用好其查询接口就能获取相似度最高的 vector 和 payload。
私有数据整合
通过上述的操作,我们已经可以把流程串起来了,下图是网友整合的一张交互流程图,这里做下简单的说明:
- 首先对原始文本内容进行切割,保证不超过 Embeddings 模型的 tokens 限制,拆分成多个 chunk
- 逐一对 chunk 调用 Embeddings 模型后获取对应的 vector 向量后,存储本地的向量数据库,关键的数据主要是 vector 值即 chunk 内容
- 根据用户问题调用 Embeddings 模型后获取该问题的 vector,在本地向量数据库进行查询,可以获取相似度 TopN 的 chunks
- 把 TopN 的 chucks 作为 chat 接口的 context,再加上用户问题作为 Prompt,通过 GPT 模型获取相应的结果
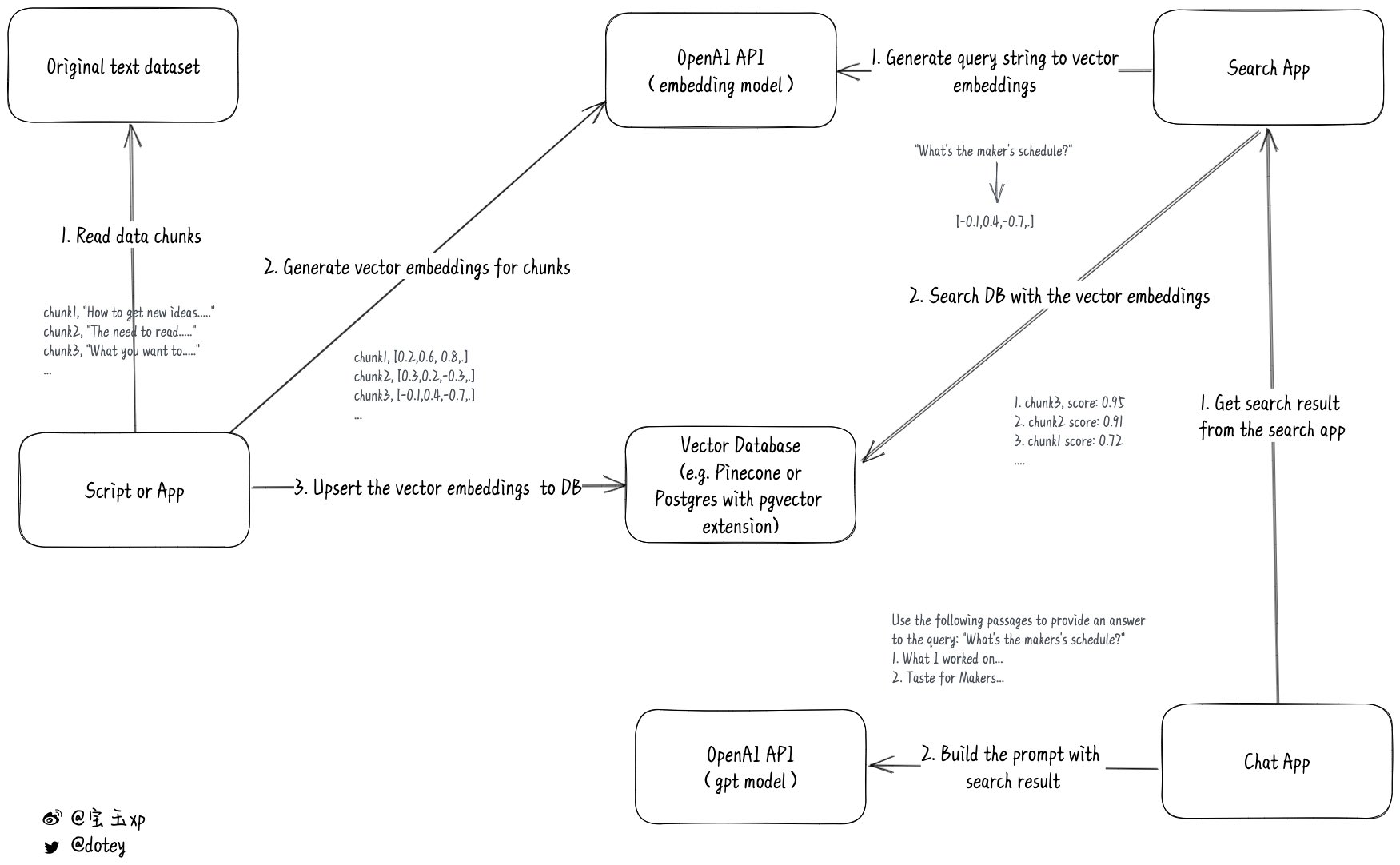
这里再补充说明下为什么通过这种方式能够做到整合的效果,核心的原理就是先利用问题在本地找到相关性最高的数据,然后再把数据放到 GPT 的 context 里,这个时候虽然模型是 2021 年训练的数据,却可以结合你上下文中你提供的资料来做问题的解答。相当于我们其实是通过 Embeddings 模型来过滤出跟这个问题相关的材料,再让 GPT 结合这些材料用自然语言表达出来。
总结
本文主要讲述了如何基于 OpenAI 的 GPT 模型,绕过 tokens 限制从而整合私有化数据,通过此功能可以衍生出大量的应用,比如可以打造个人知识库问答,让 GPT 总结一本新书的内容,还有很多结合场景,后续可以介绍。上述的方案目前也无需自行实现,已经有相应的开源 LLM 框架做了封装,比如 LangChain,LlamaIndex 等,还有 OpenAI 新发布的 Chat Plugins 功能也是非常强大,后续可以介绍下。