SkyWalking轻量级队列内核
前阵子有人评判SkyWalking的客户端的实现设计上不符合业界规范,说Java客户端存在导致JVM OOM的缺陷。抛开争论,我们先来研究下SkyWalking的轻量级队列设计,再来讨论此具备争议性的话题。(本文基于SkyWalking 8.2.0版本源码,及Trace数据上报为例)
轻量级队列
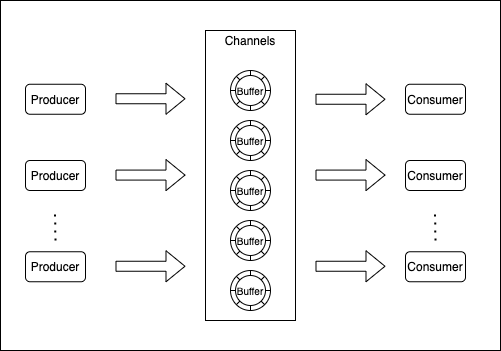
何为轻量级队列内核?SkyWalking内部为了解决多线程内部通信问题,实现了一套轻量级的无锁环形内存队列,在很多基础的功能都有使用。为了了解轻量级队列,首先要介绍了几个核心对象:
- Buffer,用来存储数据的环形数组。
- Channels,用来储存多个Buffer的通道。
- DataCarrier,轻量级队列的操作入口工具类。
Buffer
Buffer对象实现了QueueBuffer接口,核心操作主要有:
- save(T data)。保存数据到buffer环形数组中。
- obtain(List
consumeList)。从环形数据获取数据到指定的列表中。
核心的几个成员变量有:
- buffer,真正存在数据的数组
- strategy,存放策略,当准备写数据时原来的数据还未被消费的处理机制,目前有两种策略:
- BLOCKING,阻塞等到到旧数据被消费后再写入
- IF_POSSIBLE,写失败时会有重试n次的机制,如果都失败则丢弃
- index,数据写入的索引记录器,当数组写到尾部时会自动回到首部,从而形成环形数据的机制。
1 | public class Buffer<T> implements <T> { |
Channels
Channels对象包含了一组Buffer对象,核心的几个成员变量有:
- bufferChannels,如果策略IF_POSSIBLE,默认是Buffer对象数组
- dataPartitioner,Buffer分配器,往Channels写数据时需要先选择一个Buffer。默认有两种实现:
- SimpleRollingPartitioner,简单的轮询bufferChannels数组
- ProducerThreadPartitioner,根据生产者线程的ID取模,找到对应的Buffer
1 | public class Channels<T> { |
DataCarrier
DataCarrier是轻量级队列的操作入口,其包含了一个Channels对象,以及produce和consume方法。
核心成员变量:
- channels,写入的数据的入口,内部封装的Buffer分配逻辑
- driver,数据消费的驱动器
1 | public class DataCarrier<T> { |
通过以上的核心对象的介绍,轻量级队列的基本操作流程如下图所示:
- 生产者线程会使用DataCarrier的produce方法生产数据
- 数据都是通过Channels对象写入,写入时需要先找到对应的Buffer
- Buffer找到可写入的位置,写入真正的数据
- 消费者线程再从Buffer获取数据进行处理
生产消息
数据产生
Trace数据生成后会回调TraceSegmentServiceClient#afterFinished,调用carrier.produce生产数据。
1 | public void afterFinished(TraceSegment traceSegment) { |
数据分发
DataCarrier#produce会使用Channels对象的save方法,里面分装了分发逻辑。
- 首先会通过dataPartitioner获取到指定的buffer对象
- 通过buffer对象save写入数据,如果写入失败根据策略还有重试写入的机制
1 | public boolean save(T data) { |
数据储存
真正存储数据比较简单,通过Buffer的原子类index,找到对应的位置写入数据。
- 如果对应的位置数据为空,则直接写入数据
- 如果对应的位置已有数据,则返回false表示写入失败,由上层的Channels根据策略判断是否重试
1 | public boolean save(T data) { |
消费消息
消费驱动
在TraceSegmentServiceClient#boot初始化时会初始化DataCarrier,默认的CHANNEL_SIZE为5,BUFFER_SIZE为300,并会显示设置策略为IF_POSSIBLE,消费线程数为1。
1 | public void boot() { |
在调用DataCarrier#consume时,触发了ConsumeDriver#begin消费驱动的初始化,会创建消费线程处理,每个线程会无限循环获取Buffer里的数据,默认每次循环会间隔20ms。
1 | public void run() { |
数据分配
数据消费时需要考虑避免重复消费,即需要保证线程安全性。那么每个Buffer只能由一个消费线程处理,一个线程可以处理多个Buffer。
假设有CHANNEL_SIZE=5,消费线程数量为2,那么分配如图所示:
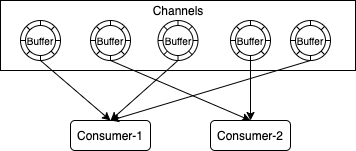
1 | private void allocateBuffer2Thread() { |
数据处理
在每个消费线程里获取所有Buffer的数据到一个集中的数组后,会调用TraceSegmentServiceClient#consume,把数据通过gRPC的方式发送到后端服务。
TraceSegment
分析完SkyWalking的轻量级队列实现,需要解释下为什么有开头的争论。内存队列基本上都设置了固定大小,并且默认是非阻塞的方式,发送失败的基本都会被丢弃,这么设计时比较合理的,也不太可能出现OOM影响业务。
TraceSegment这个概念是SkyWalking提出的,介于Google Dapper提出的Trace Tree与Span这两个概念之间,表示一个进程单次处理涉及的所有Span,这些所有Span形成一个Segment,作为上述的Buffer存储的实际对象。Segment的好处是打包了span上报成功后基本上能得到这个Segment内完整的Span数据,为什么说是基本上?因为单个segment默认最多存放300个span,多了会丢弃,这个可以参数可以调大,但是还是建议减少不必要的span,便于链路分析时减少干扰。
TraceSegment的形成是靠栈实现的,每次创建span时就压入栈,每个span完成时就会出栈。所以每次span完成时并不会直接上报数据到后端,需要等待整个Segment完成。相关源码可看TracingContext#finish的activeSpanStack.isEmpty()判断。
1 | private void finish() { |
如果某一瞬间有大量的并发请求,创建了大量的span,并且span都没有stop,span都存在栈中,那么内存是有可能存在大量的span导致OOM的。但是这种可能性是极小的,假设一个进程开了1000个线程,每个线程执行时包含了20个span,那么某一瞬间所有栈里存储的span最多也就20000个span,每个span的大小取决了存放的内容与扩张属性,一般来说这并不会耗费多少内存。默认参数加上稳定的插件基本上是没问题的,除非使用者使用很不合理,设置了极端的参数配置等。
总结
回顾本文,主要讲述SkyWalking内部实现的轻量级内存队列原理,重点谈论了几个核心的对象,以及如何发送消息与消费消息。最后针对SkyWalking的TraceSegment设计所有简单描述。有兴趣的同学可以深入了解Apache SkyWalking各功能模块,对架构设计上会有很大的帮助,也可以参与社区的讨论交流,了解SkyWalking如何实践Apache的开源文化。