分布式唯一ID的方案与实现
在互联网架构演变的过程中,分布式唯一ID被广泛使用。常见的解决方法有UUID,基于数据库的方案等,本文重点来谈谈最最常用的一个方案——Snowflake算法。
什么是Snowflake算法
Snowflake是一种可以大规模生成唯一ID的算法,它基于某些规则来保证。
2011年Twitter公司在迁移MySQL数据到Cassandra时,需要一种新的方式来生成ID,因为Cassandra没有提供相应的唯一ID生成算法,所以诞生了Snowflake算法。
Snowflake生成的ID是一个64bit的long类型,由以下3个部分组成:
- 41位时间(存毫秒值,可以自定义起始时间,可使用69年)
- 10机器码,最大允许1024台机器
- 12位序列号,每台机器每一毫秒最多可产生4096个序列号
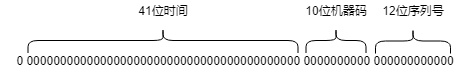
除去第1位符号位,剩余63位可以保证1024台不同的机器每毫秒可产生4096不同的ID。换句话说,就是理论上每台机器每秒可产生409.6w个不同的ID,且最多可部署1024台机器。
强依赖系统时钟
Snowflake算法唯一不好的就是强依赖系统时钟,一旦系统时钟回拨了,那么就有可能产生重复的ID,这是不可以接受的,所以我们要想办法避免时钟回拨,或时钟回拨时要有告警,并停止生成ID。
部署架构
在微服务架构的影响下,对分布式唯一ID的落地,我总结了两种部署架构,并讨论起利弊。
独立部署型
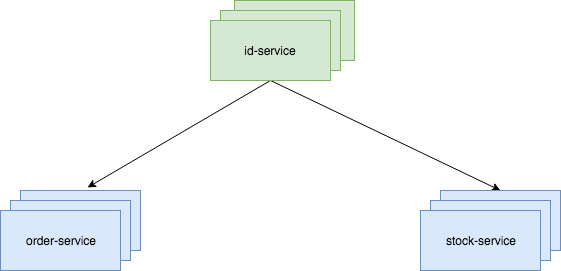
如上图,把id生成单独做成一个服务,对外提供接口调用,如订单服务order-service需要一个唯一ID时就发起一次调用,库存服务stock-service也是同样。由id-service内部保证唯一。
优点
- id全局唯一。所有应用系统的id都不会重复
缺点
- 性能差,获取id时需要发起调用。就算做成批量获取,还是需要网络消耗
- 强依赖,对id-service要求极高,一旦出问题,业务系统全部不可用
嵌入部署型

如上图,嵌入部署的话,意思是把id-service的逻辑做成工具类,直接跟着应用系统的集群一起部署,每次获取id无需走网络调用,直接本地调用工具类生成即可。
优点
- 性能好,直接本地工具调用,内存直接获取
- 弱依赖,应用之间互相独立,互不影响
缺点
- id应用唯一。只能保证同个应用下id唯一,跨应用id有可能是相同的
实现方案
具体实现主要关注两个问题:机器ID自动下发及防止时钟回拨。
机器ID自动下发
关于机器ID下发的具体实现,我们可以利用zookeeper的特性来实现。我们以应用为维度,每个应用都注册到/snowflake目录下,每个应用下有两个目录,servers目录以及instances目录。servers目录下的节点均为持久化节点,instances目录下的节点均为临时节点。
1 | /snowflake |
下面流程展示了服务启动时获取机器ID的流程:
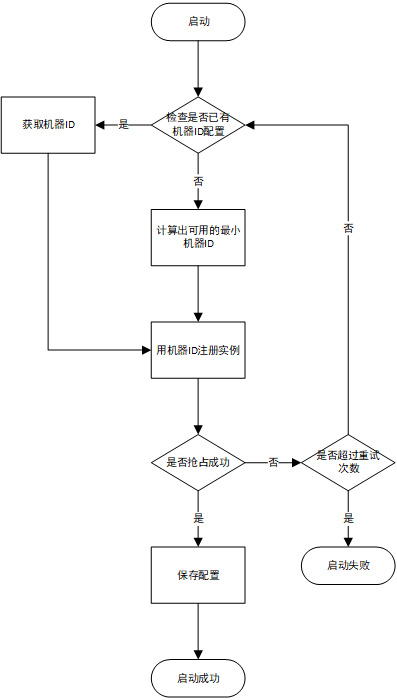
- 首先应用启动,得到自身应用相关信息,如应用名称,IP地址及端口等
- 根据应用名称在对应的
servers目录下,查找是否有匹配自身IP及端口的节点 - 如果有跳到步骤4,没有则在
servers下所有子节点中,从0~1023中选出未被使用最小的机器ID - 获取到机器ID去
instances目录下创建临时节点 - 如果创建成功,则保存配置到
servers中,并启动成功;如果创建失败,则判断重试次数,跳回步骤2或启动失败。
为什么要这么做?用0~1023的随机数去instances抢占也可以,为何还要保存配置到servers目录下?
这么做的原因主要是尽可能地保证机器ID稳定,不变化。好处是可以缓存这个稳定的机器ID到本地磁盘文件,在zk不可用时,直接读取本地磁盘文件记录的机器ID启动,弱化了对zookeeper的依赖。
防止时钟回拨
关于机器回拨的问题,可以分两种情况:运行时回拨和启动时回拨。
运行时回拨
这种情况可以在启动后每次生成id时在内存中用变量记录上一次的时间,一旦回拨可以及时发现,如回拨几毫秒可以选择等待,如过大范围回拨则抛异常,服务不可用。
启动时回拨
在进程启动时时钟已经发生回拨,这是用内存变量来记录上一次的时间以及没有多大作用了。这时本服务器的时钟已不可信,应该通过网络访问外部的时钟来判断。如开启NTP同步,基本可避免启动时已经发生回拨;美团的leaf-snowflake则是通过rpc的方式访问其他服务的系统时间做平均值来参考。只要启动时发现时钟回拨,则启动失败。
总结
本文是在工作中重构原有类snowflake算法使用不当情况下,做了一些探究并做了新版的实现。参考了一些现有的开源项目,和一些文章。如Twitter最早的官方材料,百度的uid-generator,美团的Leaf文章,以及微信的seqsvr等。
根据业务情况,采用了嵌入部署型的snowflake,借鉴了美团leaf-snowflake的一些实践,并用本文所介绍的zookeeper自动下发机器ID的方案实现了分布式唯一ID生成的功能。